
Author: Carlos Salas Najera
ChatGPT3 has sparked the imagination of popular culture over the last months due to its impressively detailed answers with human-like overtones. There have also been certain controversies, such as the use of ChatGPT3 for scholar research writing, proving incorrect and ambiguous answers or, even worse, generating inflammatory statements such as endorsing the invasion of Ukraine by Russia. For the full list of events surrounding the worldwide adoption of ChatGPT3, I encourage you to visit the Wikipedia profile about this topic.
Although I will introduce ChatGPT3’s nuts and bolts here, the focus of this article is more oriented towards a pragmatic application of ChatGPT3 for investment research purposes, particularly fundamental qualitative analysis. The final section will be showcasing a hands-on case of how to conduct qualitative analysis (SWOT and PESTEL analysis) of a company using very simple Python snippets to access ChatGPT3. Last,but not least, a brief evaluation of ChatGPT3’s output will be carried out in order to understand advantages and disadvantages of this new tool.
The Late Show with ChatGPT3
A brief interview with ChatGPT3 is presented in the next image where I mainly asked about its specific functions to perform, the pros and cons of using it as well as its role in the investments industry, particularly as a productivity enhancer when conducing qualitative analysis of a company.
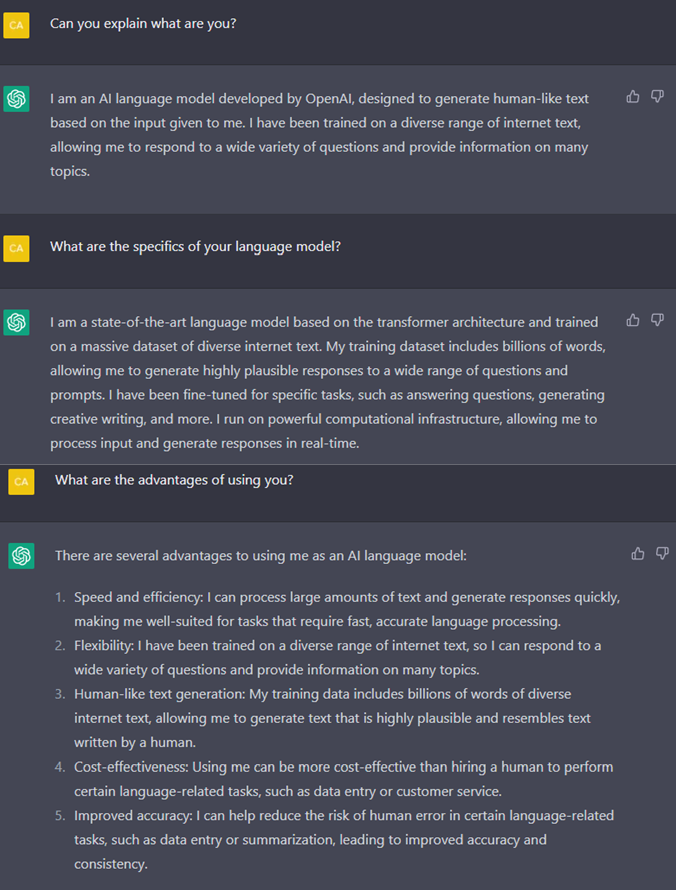

The key takeaways of the interview are showcased below:
- ChatGPT3 defined itself as an AI language model developed by OpenAI to generate human-like text based on the transformer architecture and trained on a massive dataset of diverse internet text. That said, ChatGPT3 self-defined itself as a Machine Learning tool instead of an AI when challenged about its capabilities.
- Advantages summary: speed, efficiency, flexibility, human-like text generation, cost-effectiveness, and improved accuracy.
- Disadvantages summary: limited understanding, lack of creativity, bias, dependence on data, and limitations in context.
- When asked about the most important contribution it can make to the investments industry:
“I believe the most important contribution I can make to the finance industry, particularly the investments industry, is to support and augment the work of human professionals by providing quick and accurate access to information, automating repetitive tasks, and helping to ensure compliance with regulations”.
- When asked about how to help human beings in an investment research task such as analysing a company, ChatGPT3 enumerated the following tasks:
- Data Processing: “I can process and summarize large amounts of financial data, including financial reports, news articles, and market data, helping to identify key trends and insights relevant to equity research.”
- Financial Modelling: “I can assist in the creation of financial models, providing insights into a company's financial performance and future prospects.”
- News and Market Analysis: “I can provide summaries of news articles and market trends, and highlight information relevant to equity research decisions.”
- Competitor Analysis: “I can provide information on a company's competitors, including market share, financial performance, and recent developments.”
- Question Answering: “I can answer questions related to equity research, providing quick and accurate responses to information requests.”
A funny answer when challenging ChatGPT3 about its capabilities is presented below as a cautionary tale about using mindlessly this tool without further checking.

ChatGPT3 in a Nutshell
GPT is the acronym of “Generative Pre-Trained Transformer”:
- Generative: predicting next word.
- Pre-Trained: ex-ante training with large amounts of data.
- Transformer: encoder-decoder ANN (Artificial Neural Network).
- ChatGPT: GPT fine-tuned for conversations.
As team OpenAI explains in its official website, they trained this model using Reinforcement Learning from Human Feedback (RLHF) by training an initial model using supervised fine-tuning. The next lines cite OpenAI’s exact process for training ChatGPT3:
“ … human AI trainers provided conversations in which they played both sides—the user and an AI assistant. These trainers had access to model-written suggestions to help them compose their responses to create a new dialogue dataset.”
“To create a reward model for reinforcement learning, we needed to collect comparison data, which consisted of two or more model responses ranked by quality. To collect this data, we took conversations that AI trainers had with the chatbot. We randomly selected a model-written message, sampled several alternative completions, and had AI trainers rank them. Using these reward models, we can fine-tune the model using Proximal Policy Optimization, a policy gradient method for reinforcement learning. We performed several iterations of this process.”

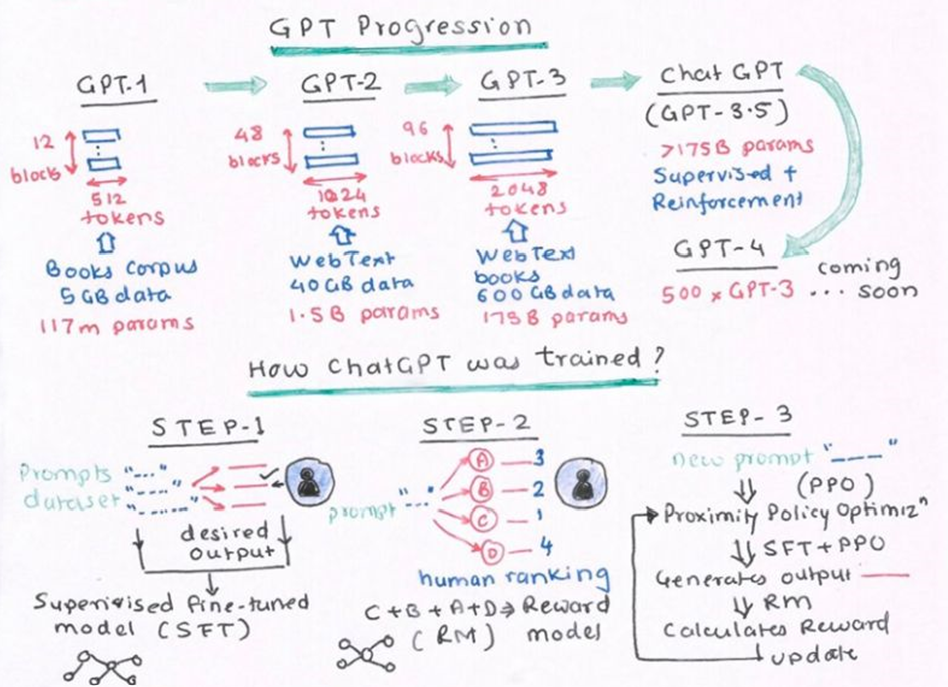
The former explanation is rather technical for those readers early in their NLP and GPT learning curve, yet the next illustration effectively summarises the evolution of GPT models and its training process in layman’s terms (source: Yogesh Haribhau Kulkarni). I recommend the readers with genuine curiosity about this model to, firstly, acquire a solid NLP (Natural Language Processing) background by reading the introduction to the last article on this topic and visiting the educational resource of the CFA UK website to understand NLP building blocks essential to understand the model i.e. embedding methods, Word2Vec, or BERT.
The Battle of the Century: ChatGPT3 vs Bard
In January 2023, Microsoft announced the third phase of the long-term partnership with OpenAI following up previous investments in 2019 and 2021. What was particularly exciting was the introduction of the Azure OpenAI service as a way to blend ChatGPT3 capabilities with the power of Microsoft’s cloud offering.
Countering Microsoft’s initiative, Google announced "Bard" in early February 2023. Bard will be integrated into existing search capabilities with the model being based on its LaMDA project (Language Model for Dialogue Applications), which is trained with questions asked based on information gathered from the web.
Following up this statement, Microsoft’s CEO Satya Nadella announced an “all new, AI-powered Bing search engine and Edge browser”. In other words, Microsoft’s Bing is a new contender in the search engine niche. That said, the ultimate goal of Microsoft is the lucrative online advertising industry, which is currently dominated by Google with a 27.7% US market share of ad spending, and followed by Facebook with 24.2% and Amazon with 13.3% (source: zippia.com).

The US market revenue reached $59.2bn, making more than one third of the total global pie of $766bn, which is projected to grow by 9.42% CAGR (Compounded Annual Growth Rate) within the period 2023-2027. This will result in a market size of US$1,005bn in 2027 (source: statista). Therefore, it’s quite clear what the ultimate objective for Microsoft is moving forward.
Hands-on Lab – Accessing ChatGPT3 via Python
This section will set up a Python workstation to access ChatGPT3. Fortunately, the reader will find the following Python code very accessible,even if you are a Python beginner.
Firstly, the reader should visit OpenAI in order to create an account and apply for an API key to access OpenAI services. The next step is to open a terminal to install OpenAI library:

If the reader is experiencing issues in this initial step, I recommend reviewing the last article on how to deal swiftly with third-party library installations.
The OpenAI Python library is the most convenient way to use ChatGPT3 in our Python working environment, as it will allow to let us access OpenAI’s API, which includes a pre-defined set of classes designed for multiple tasks.
Firstly, you will have to create a config.ini file to store the API key generated on the OpenAI website. Open a text editor such as notepad and type your API key in the next format and save it as config.ini file in a secured folder/path in your computer.

Afterwards, we can launch our favourite IDE (Spyder, PyCharm, VSC, etc) or notebook to start coding the program in order to access ChatGPT3.
Firstly, the required libraries must be loaded along with the login to OpenAI using our API Key and the library configparser. This is a recommended cybersecurity practice in order to refrain from pasting our API key in the script as values that could be inadvertently obtained by undesirable, unknown parties.

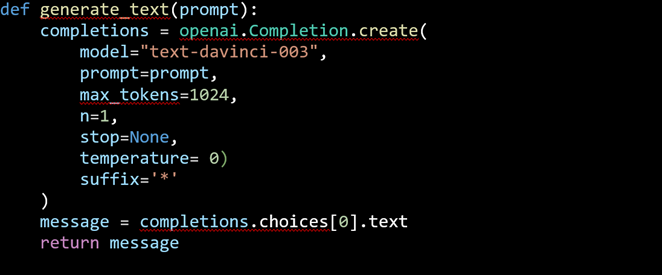
In the next snippet, a bespoke function is developed in order to obtain the output for our queries to ChatGPT3. The core of this user-defined function is OpenAI’s library function openai.Completion.create whose arguments can be quickly described as follows:
- model: ID of the model to use. This example uses the latest model “text-davinci-003” trained internally by OpenAI. To get a deeper grasp about OpenAI models visit the next link.
- prompt: query to ask ChatGPT3.
- max_tokens: ChatGPT3 output word limit.
- ·n: number of answers to be generated in each call with a maximum value of 10. The example below is limited to 1 to avoid running out of the freely available token quota per user.
- stop: defaults to None. This argument allows to enter strings or arrays with a maximum of 4 sequences where the API will stop generating further tokens.
- temperature: value between 0 and 2 i.e. the higher this value, the more random the output becomes and viceversa. In layman’s terms, a value of nil will limit exploratory properties of the algorithm and force it to yield similar answers after every call.
- suffix: specific string character to be used as marker for tabular answers.
Conducting Qualitative Analysis with ChatGPT3
A reasonable amount of time has been allocated to conduct an evaluation of ChatGPT3 as a tool to carry out qualitative analysis of The Coca-Cola Company (ticker: KO US). Many query permutations were tested to generate and filter those with the highest degree of coherent and reasonable output.
The next snippet continues the example by defining a company name and ticker variables that will be used later in the analysis. In addition, the next queries focus on running PESTEL analysis, which are defined using the next variants:
- Q1: Query using the company name and acronym i.e. PESTEL.
- Q2: Query using the company name and the full term i.e. Political, Economic, Social, Environmental and Legal.
- Q3: Query using the company ticker and acronym.
- Q4: Query using the company ticker and the full term.
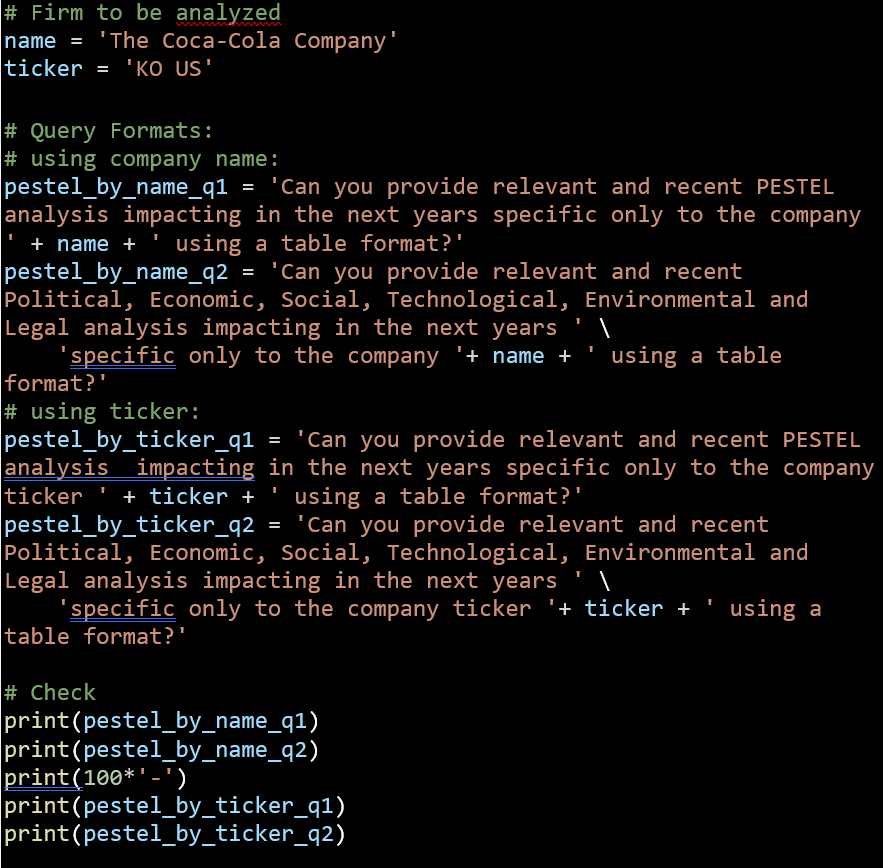
The next step will be to call the user-defined functions for each one of the queries. The next snippet is an example used for the first query on PESTEL analysis using the acronym and the company name.

Repeating the same operation for the remaining three queries provides an interesting illustration of how ChatGPT3 output can vary dramatically depending on the query input as it is displayed in the next table.


This first comparison is a good way to compare ChatGPT3’s diverse output depending on the question provided:
- Q3 (ticker + acronym) delivers the shortest answer with rather generic details as well.
- Q1 (name + acronym) also delivers a short answer but with additional details compared to Q3.
- Q2 (name + full term) and Q3 (ticker + full name) display a rather similar output in terms of length and details specific to the company.
Overall, using the full term instead of the acronym ( i.e. PESTEL) seems to be delivering more detailed and idiosyncratic answers. But is this phenomenon repeating for other qualitative analysis methods such as SWOT?
The answer to this question can be easily answered by tweaking the previous code and asking the same questions replacing:
- PESTEL for SWOT in Q1 and Q3.
- “Political, Economic, Social, Environmental and Legal” for ”Strengths, Weaknesses, Opportunities and Risks” in Q2 and Q4.
The output for this new set of queries after carrying out the appropriate snipped tweaks is presented in the next table.


Once again, comparing ChatGPT3’s answers to different queries can unveil interesting insights:
- Q3 (ticker + acronym) this time is unable to retrieve an answer.
- Q2 (name + full term) and Q4 (ticker + full name) deliver a short answer although the former seems to be more spot on answer with lines more idiosyncratically related to Coca-Cola.
- Q1 (name + acronym) delivers the most convoluted answer with many more details but misses some of the points made by Q2.
Therefore, ChatGPT3 seems to be inconsistent when dealing with acronyms since the quality of the answers delivered using the acronym “SWOT” analysis are superior to the quality of the answers when using “PESTEL”.
Beware that due to ChatGPT3’s ongoing learning and depending on the arguments utilized in the openai.Completion.create function (e.g. temperature, etc), the output delivered might differ from the one observed in the previous screens when the reader performs the same queries using a local machine.
A Few ChatGPT3 Tips for Investors
Some tips for investment decision-makers willing to smooth the process of obtaining qualitative insights from ChatGPT3:
- Avoid ticker nomenclatures: early tests with ChatGPT3 resulted in incorrect output when deploying ticker information to identify the company’s identity. For instance, when using “KO US” (The Coca-Cola Company) without specifying a clear entity description in the string (e.g. company), resulted in spurious output: the answer provided information about the United States as a country instead of about Coca-Cola i.e. the algorithm was not able to identify “KO US” as a company despite the ticker “KO US” and got stuck in the last part of the ticker string. The last section also pointed out another ticker-related problematic scenario during a “SWOT” acronym query.
- Acronyms efficiency varies: abbreviations such as “SWOT” or “PESTEL” can be understood by the model, yet ChatGPT3’s performance does not seem to be consistent as demonstrated in the previous section. This might be a case of context as ChatGPT3 is able to link more efficiently acronym tokens (e.g. SWOT) to business-related tasks, whereas a full reference name (e.g. Strengths, Weaknesses, Opportunities and Threats) results in a more broad and generic answer.
- Narrow the context: preliminary tests using a set of brief questions resulted in outdated answers or non-relevant output. In this way, the reader should try to run simple queries such as “Please provide a SWOT analysis for the company X” to confirm how ChatGPT3 throws faulty or generic answers that might require a higher-than-expected level of human supervision. To solve this predicament is advisable to add terms such as “relevant”, “recent”, ”impacting in the next years” and “specific to the company X” to the string query passed to ChatGPT3. This results in a remarkable improvement of the output’s specificity.
Human Supervision: Challenging ChatGPT3 Analysis Output
As the previous section showcases, ChatGPT3 is able to produce an incredible amount of accurate output that might save valuable time in our busy schedule. Qualitative analysis is one of the most time-consuming tasks for an investment decision-maker, for which reason human analysts could apply ChatGPT3 to focus on those parts where they can add more value to the investment process and, most importantly, apply common-sense to ChatGPT3’s output in order to verify its content materiality, identify vague statements and amend incorrect assessments.
For instance, some human analysts might argue that one of the most valuable parts of Coca-Cola is its brand value AKA intangible value. Nevertheless, some preliminary queries run at the outset of the analysis were answered by ChatGPT3 with controversial sentences: “Low product differentiation” named as one of Coca-Cola’s main weaknesses. Human analysts covering Coca-Cola would probably disagree with this assertion as it seems ChatGPT3 is issuing a generic statement that is more intrinsically intertwined with the aggregate soft drinks industry rather than to the idiosyncratic traits of Coca-Cola.
Conclusions
Probably the best answer of the interview with ChatGPT3 was this one:

In other words, AI claims by many start-up firms nowadays are pure and simple marketing gimmicks that hide a more simple and less fascinating tool that initially introduced. But the phonetics and implications of “AI” (Artificial Intelligence) are always more appealing for the consumer than the term “ML” (Machine Learning).
Overall, ChatGPT3 should be use by investment decision-makers as tool that can spark their productivity rate and allow them to focus on what matters most during the research and due diligence stage. ChatGPT3 is not perfect as demonstrated in this article and, as a result, human supervision is still required to ensure the relevance and integrity of the output you receive.
PIC and Links
L/S Portfolio Manager | Lecturer & Consultant
• https://www.linkedin.com/in/csalasls/
• https://twitter.com/CarlosSNaj
